
疗学术扩张治疗学术交换会治疗学术是干嘛的职业治疗学术聚会约请函
4月5日,中国揣测机学会(CCF)推选的A类国际学术聚会SIGIR 2025论文汲取结
学术推广
学术推广
4月5日,中国揣测机学会(CCF)推选的A类国际学术聚会SIGIR 2025论文汲取结果发表。中国国民大学高瓴人为智能学院师生有20篇论文被任用。SIGIR全称为[ACM Special Interest Group on Information Retrieval](国际揣测机协会消息检索大会),被以为是消息检索周围的顶级国际聚会之一。SIGIR 2025聚会将于7月13日至17日正在意大利进行,显示人为智能与消息检索周围的最新发展和打破性咨议。

论文概述:比来的咨议浮现大发言模子(LLMs)与基于预磨练发言模子(PLM)的神经检索器之间存正在丰富耦合,导致了一种被称为源误差(source bias)的形势:假使语义相当,检索模子仍目标于对LLM天生实质给予更高的闭连性评分。跟着LLM的速捷兴盛和遍及行使,有用缓解源误差已成为消息检索体系可陆续兴盛的首要挑衅。现有技巧首要从检索模子侧入手,以“被动防御”的方法正在天生实质进入检索流程后再举行干与。然而,这类计划正在工业履行中面对高频模子更新、高本钱维持等题目,且难以从基本上管理源误差。为此,咱们提出了一种从LLM侧启程、正在数据天生阶段“主动对齐“输出的新思绪,并策画了一个用于源误差缓解的LLM对齐框架。咱们起初通过主动化的偏好数据修建流程天生了10,830条高质料对齐样本。该流程应用LLM对原始人类创作的文档举行多次改写,并借帮PLM-based检索模子为每条改写文档打分,修建出具备细粒度偏好分其它偏好对。为足够应用这些连气儿型偏好分值并晋升对齐效用,咱们正在战略磨练中引入了带权重的耗损函数,同时正在梯度领悟中说明该技巧拥有杰出的抗噪才具。正在多个检索数据集与PLM-based检索器上的试验表白,利用咱们的技巧对齐后的大模子不只能明显低落源误差,同时还能维系其通用才具。

论文概述:天性化推选体系用心于预测用户笑趣,已正在各种行使中明显晋升了用户体验。然而,现有技巧凡是是通过拟合细粒度标签(如点击标签)来隐式筑模用户偏好,却往往渺视了输入数据中自身包含的粗粒度笑趣消息。纯洁依赖细粒度标签能够会对笑趣筑模发作负面影响,束缚模子功能,由于这些标签正在实际场景中往往带有不成避免的噪声。其余,人人半现有技巧正在面临缺乏维持样本的境况时,难以有用筑模用户的多粒度笑趣,特别正在长尾形势紧张的境况下,功能显露不佳。为明了决上述题目,咱们提出了一种簇新的研习框架——多粒度笑趣预测框架(MGIPF),以更好地筑模用户的多样化笑趣。与以往管事分歧,咱们的中央情念是同时应用粗粒度和细粒度的笑趣消息来监视模子磨练。整个而言,咱们引入了一种伪标签技巧,从原始数据中显式开采用户潜正在的多粒度笑趣,并策画了粗粒度笑趣预测模块,协同应用多粒度监视信号来巩固对低频商品的研习。相应的粗粒度耗损被软加权,以斟酌正负样本正在多粒度偏好上的置信度分别。值得夸大的是,该框架轻量敏捷,可能有用适配主流推选模子,设备端到端的完备磨练流程。咱们正在三个公然数据集进步行了大批试验,验证了该技巧的有用性。
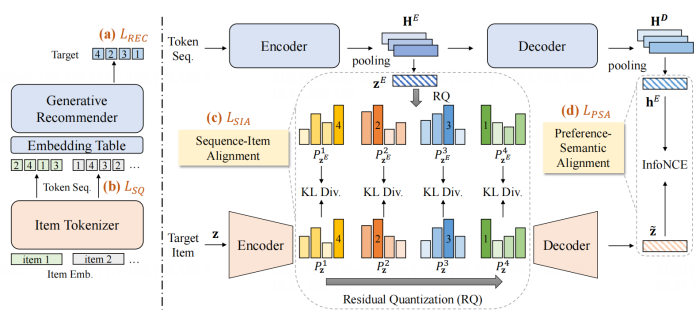
论文概述:天生式推选动作一种直接天生物品标识符以杀青推选义务的新范式,渐渐成为推选体系周围的咨议热门。只管具备潜力,这类体系面对的首要挑衅正在于怎么修建与推选体系杰出适配的有用物品标识符。现有技巧凡是将物品分词(item tokenization)流程与天生式推选磨练割据为独立阶段,导致物品分词与推选义务存正在误差。为管理这一闭节题目,咱们提出ETEGRec,通过同一框架将物品分词与天生式推选有机整合。该框架基于双编码器-解码器架构修建,包蕴物品分词器和天生式推选器两个中央组件。为了完成这两个组件之间的常识统一,咱们策画了一种面向推选的对齐战略,其包蕴两个优化宗旨:序列-物品对齐与偏好-语义对齐。这些宗旨有用耦合了物品分词器和天生式推选器的研习流程,鼓励二者的协同巩固。其余,咱们提出了瓜代优化时间以确保全面框架平静高效的磨练。正在公然基准数据集上的试验结果说清晰咱们技巧的有用性。
论文概述:正在当今的数字境遇中,虚伪信息通过社交搜集的速捷宣称带来了明显的社会挑衅。现有的人人半检测技巧要么利用守旧的分类模子,但这些模子存正在可表明性差和泛化才拥有限的题目;要么为大型发言模子策画特定的提示词,让其直接天生表明和结果,但这种方法未能足够阐述大型发言模子的推理才具。本文提出了一个基于大型发言模子的多智能体体系,名为 TruEDebate(TED),旨正在晋升虚伪信息检测的可表明性和有用性。TED 引入了受正式争吵筑设启示的庄重争吵流程。咱们的技巧包蕴两个闭节的更始组件:DebateFlow Agents 和 InsightFlow Agents。DebateFlow Agents 将多个智能体分为两个团队,一方维持信息的真正性,另一方则提出质疑。这些智能体次第举行开篇陈词、交叉质询、反对和总结陈述,模仿相像人类话语领悟的庄重争吵流程,从而完成对信息实质的深刻评估。与此同时,InsightFlow Agents 囊括两个特意的子智能体:Synthesis Agent 和 Analysis Agent。Synthesis Agent 掌握总结全面争吵流程,供给一个总体意见,确保评估的同等性与周全性。Analysis Agent 采用一个具备脚色感知的编码器和争吵图机闭,贯串脚色嵌入,并通过注意力机造筑模争吵脚色与论点之间的交互,从而得出最终判决。结果表白 TED 框架正在多个评议目标上优于守旧技巧。更首要的是,TED 晋升了虚伪信息检测的可表明性,通过揭示逻辑推理和机闭化的争吵流程,从而得出精确的结论。
论文概述:无偏排序研习(Unbiased Learning to Rank,ULTR)旨正在利用汗青点击日记来磨练排序模子。现有的无偏排序研习管事聚焦于缓解点击日记中存正在的百般误差,如场所误差、信赖误差和表现误差,以取得盘查-文档对的真正闭连度。然而,他们幼看了磨练数据(即汗青点击日记)和测试数据(即正在线数据)之间的固有的分散迁徙。正在本文中,咱们起初正在一个真正的开源ULTR数据集上验证和领悟了分散迁徙题目。为管理这一题目,咱们提出了分散鲁棒的无偏排序研习技巧(Distributionally Robust Unbiased Learning to Rank, DRO-ULTR)。整个地,咱们为现有的两类无偏排序研习技巧策画了两种基于分组的分散鲁棒优化框架,区别利用逐点的点击预测耗损和列表式反原形排序耗损。试验结果表白,咱们提出的框架可能巩固多种无偏排序研习技巧对分散迁徙的鲁棒性。
论文概述:流式推选正在互联网实质分发中阐述着首要效用,它可能依据用户的及时活动与偏好,自适合地调动推选战略或实质,晋升用户体验。跟着直播业的火速兴盛,直播流推选动作流式推选的首要行使之一,受到了遍及闭切。精准的直播流推选不只能够帮帮用户速捷浮现感笑趣的直播实质,还可帮力主播吸引更多观多,对直播平台的生态意思庞大。然而,直播顶用户反应数据寥落题目却紧张限造了直播流推选的精确性。现有的跨域推选技巧首要依赖于重叠用户或物品正在分歧周围间举行消息迁徙,而幼看了非重叠短视频与主播之间的强联系性。本文提出了多图对照研习框架MGCCDR,该框架应用重叠用户与非重叠物品来巩固跨域消息的通报有用性。通过全部图研习全部表现,设备主播与短视频之间的联系,修建了用户、作家与短视频之间的二部图,并引入多图研习技巧,从宗旨域视角、源域视角以及跨域视角捉拿用户及时偏好。为了应对分歧图正在最终直播流推选义务中进献水准的分别,策画了一种基于注意力机造的技巧,有用整合图表现以鼓励跨域消息的动态咸集。正在贸易和公然数据集上的试验表白:所提出的MGCCDR技巧正在功能上明显优于现有的技巧。
论文概述:正在数字消息爆炸的时期,真正天下中的消息获取义务往往须要多步的网页寻乞降丰富的消息整合,流程繁琐且容易堕落。针对这一挑衅,本咨议基于全部指导的蒙特卡洛树寻求提出了一种全新的大发言模子驱动的寻求帮手框架HG-MCTS。该技巧将消息获取义务修建为一个慢慢修建常识的流程,并引入追思模块、自适合子宗旨清单和多视角嘉勉机造,周全晋升丰富盘查的笼罩性与精确性。个中,自适合清单用于动态天生子宗旨,指导寻求流程笼罩丰富盘查的多个维度;多视角嘉勉机造则贯串检索质料、追求深度及义务发展境况,为寻求旅途供给反应。该技巧有用平均结果部追求与全部指导,明显删除了冗余寻求旅途,确保所相闭节消息点均被精确笼罩。
论文概述:本文聚焦于晋升大发言模子(LLM)的天性化天生才具,特别是正在用户天性化的检索巩固天生(Personalized Retrieval-Augmented Generation,简称RAG)义务中。守旧的天性化RAG技巧首要依赖现在用户的汗青文档来反响其偏好,从而晋亡故生质料,但渺视了“类似用户的汗青”也能够动作首要的消息源,辅帮现在用户的天性化天生。受推选体系中协同过滤思念的启示,本文提出了一种名为 CFRAG 的技巧,将协同过滤机造引入RAG框架,用于文本天生义务中的天性化筑模。CFRAG面对两个首要挑衅:(1)正在缺乏昭彰用户类似性标签的境况下,怎么引入协同消息?(2)怎么从多个用户的汗青中有用检索维持天性化天生的文档?为管理第一个挑衅,本文通过对照研习修建用户表现,以此检索类似用户并引入他们的汗青实质。针对第二个挑衅,CFRAG策画了天性化的检索器和重排序模块,不只斟酌用户偏好,还借帮LLM的反应信号对检索器与重排序器举行优化,从而更好地效劳于天生义务。试验正在发言模子天性化基准数据集 LaMP 进步行,结果验证了CFRAG的有用性,并通过进一步领悟说明协同消息对天性化天生拥有明显晋升效用。
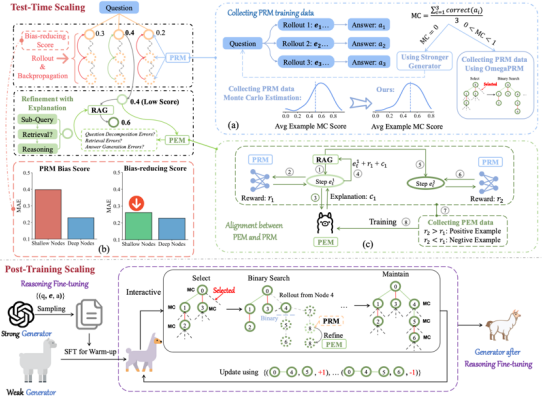
论文概述:基于检索巩固天生(RAG)的大型发言模子(LLMs)正在常识群集型义务中暴露了潜力,但其推理才具,异常是正在丰富的多步推理方面,已经有限。只管近期有咨议追求将RAG与链式头脑推理贯串,或通过流程嘉勉模子(PRM)贯串测试时寻求,但这些技巧面对多个不成托的挑衅,囊括缺乏表明、PRM磨练数据的误差、PRM评分中的早期步伐误差,以及幼看未能十足优化推理潜力的后期磨练。为明了决这些题目,咱们提出了通过可托流程嘉勉巩固推理的框架(ReARTeR),该框架通事后期磨练和测试时扩展巩固RAG体系的推理才具。正在测试时,ReARTeR引入了通过流程嘉勉模子举行的可托流程嘉勉,用于精确的标量评分,并通过流程表明模子(PEM)天生天然发言表明,完成步伐细化。正在后期磨练中,咱们应用受可托流程嘉勉指导的蒙特卡罗树寻求汇集高质料的步伐级偏好数据,并通过迭代偏好优化来优化模子。ReARTeR管理了三个闭节题目:(1)PRM与PEM之间的不可亲,通过离战略偏好研习举行管理;(2)PRM磨练数据中的误差,通过平均注解技巧并为坚苦示例参与更强的注解举行缓解;(3)PRM中的早期步伐误差,通过基于工夫差的前瞻寻求战略加以管理。正在多步推理基准上的试验结果表白,ReARTeR明显降低了推理功能,突显了其饱动RAG体系推理才具的潜力。
论文概述:对话式推选体系借帮多轮交互捉拿用户偏好并供给天性化推选,其闭节挑衅是从对话中有用知道用户偏好。过往咨议针对对话上下文消息缺乏题目,引入常识图谱、大发言模子等表部常识源,策画对齐战略用于知道偏好和推选。但用户偏好丰富,即使有富厚表部常识,精准推选仍具挑衅,且频仍用户介入会低落体验。为管理该题目,咱们提出基于天生式嘉勉模子的模仿用户,用于与体系主动交互。模仿用户对推选商品反应,帮其捉拿丰富偏好。受天生式嘉勉模子启示,策画天生式商批评分(粗粒度反应)和基于属性的商批评议(细粒度反应)两种活动,并同一为指令款式,经指令微调修建模仿用户。为平均成效与效用,模仿嘉勉指导寻求范式,交互用集束寻求,还提出高效候选排名法优化推选结果。大批公然数据集试验验证了该技巧的有用性、高效性和可迁徙性。

论文概述:本论文测试对大型发言模子正在检索巩固天生场景中,统一参数化常识与检索到的常识的机造举行追求。正在宏观层面通过常识滚动领悟,将常识应用流程划分为四个阶段:常识精辟、常识引出、常识表达和常识角逐,并察看到检索文档的闭连性会影响常识滚动。正在模块层面,开始商量了神经元激活、多头注意力机造和多层感知机正在常识整合中的分歧效用。

论文概述:公正性正在重排序义务中日益成为一个首要身分。已有咨议表白,排序精确性与物品公正性之间存正在量度闭联。然而,这种量度背后的机造仍未被足够知道。能够将重排序类比为经济生意流程中的动态。精确性与公正性的量度闭联相像于商品税负挪动流程中的耦合机造。
正在重排序中引入公正性考量,就宛若对供应方征收商品税,这种本钱最终会转嫁给消费者。相像地,物品端的公正性管造会导致用户端精确性的低浸。正在经济学中,权衡商品税从供应商(即物品公正性)向消费者(即精确性耗损)挪动水准的观点,被正式界说为弹性(elasticity)。而正在重排序义务中,公正性与精确性的量度也受到分歧物品群体间效用弹性的影响。这一洞察揭示了现在公正重排序评估的局部性——现有技巧往往只依赖简单的公正性目标,难以周全权衡算法的公正性显露。盘绕“弹性”这一中央观点,本文提出了两项首要进献:1. 咱们引入了**弹性公正弧线(Elastic Fairness Curve, EF-Curve)**动作一种评估框架。该框架可能正在分歧弹性秤谌下对算法功能举行对照领悟,从而帮帮选取最符合的公正重排序战略。2. 咱们提出了一种新的公正重排序算法ElasticRank,该算法通过弹性揣测,正在一个曲率空间中动态调动物品间的隔断。正在三个遍及利用的排序数据集上的试验说明,该技巧正在成效与效用上均具上风。
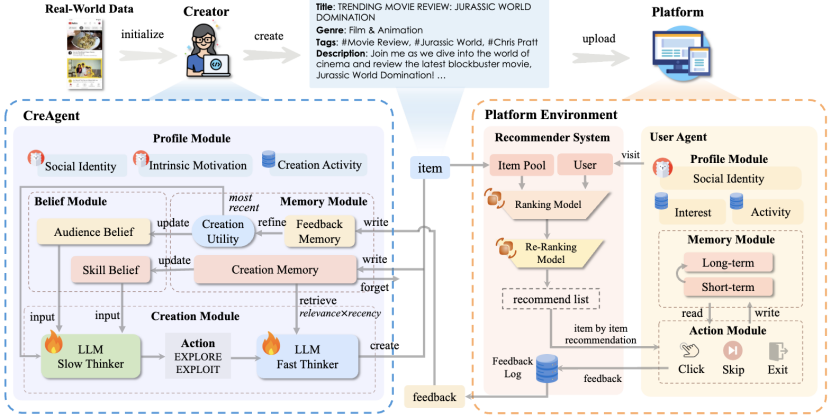
论文概述:维持推选体系(RS)的永恒可陆续性至闭首要。守旧的推选体系评估技巧首要闭切用户的即时反应(比方点击),但往往幼看了由实质创作家激励的永恒影响。正在实际天下中,实质创作家能够通过领悟用户反应和偏好趋向,战略性地创作并上传新实质到平台。只管已有咨议测试对创作家活动举行筑模,但它们凡是幼看了这些活动是正在消息错误称的条款下发作的。这种错误称源于:创作家平常只可获取本人所创作实质的用户反应,而平台则驾御完备的反应数据。然而,现有的推选体系模仿器凡是没有斟酌这一点,导致永恒评估结果不精确。为明了决这一题目,咱们提出了一种基于大型发言模子(LLM)的创作家模仿智能体 CreAgent。通过引入博弈论中的信心绪造和“速-慢头脑”框架,咱们可能有用模仿消息错误称下的创作家活动。为了进一步晋升 CreAgent 的模仿才具,咱们采用近端战略优化算法(PPO)对其举行微调。咱们的可托度验证明验表白,该模仿境遇可能较好地复现实际平台与创作家的活动,从而晋升推选体系永恒评估的牢靠性。其余,借帮这一模仿器,咱们还能进一步咨议诸如公正性、多样性等算法是否有帮于晋升分歧益处闭连者的永恒显露。
论文概述:正在线告白是电商平台的首要收入源泉。守旧的贸易模子是市廛出价正在告白拍卖中获取暴露机遇。近期咱们团队与美团团结提出了纠合拍卖这一新的告白贸易形式并已上线利用。纠合拍卖形式下一个告白位会显示一家市廛和一个品牌的赞帮bundle。与守旧形式比拟,它使平台能同时从品牌方和市廛收取用度,从而降低收益。然而,正在现实行使中,分歧的告白形式能够会吸引分歧的用户群体,实用于分歧类型的商品和品牌,带来分歧的点击量。纠合拍卖是否必定比守旧告白形式的收益更高?假若不是,有没有一种告白形式能带来更高收益?为明了决这两个题目,咱们提出了一种名为“Hybrid告白”的全新模子,如图1所示。
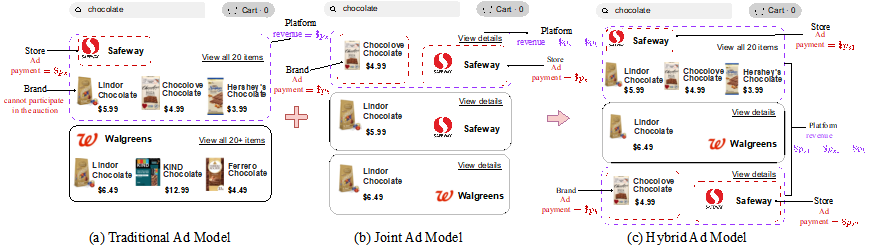
正在这种模子中,每个告白位能够分派给市廛或bundle。为了找到Hybrid告白中的最佳拍卖机造,同时确保近似勉励相容和个人理性,咱们引入了HRegNet,这是一种专为该宗旨策画的神经搜集架构,如图2所示。大批的模仿数据试验和真正数据试验表白,HRegNet天生的机造相较于已有的基准技巧明显降低了平台收入。
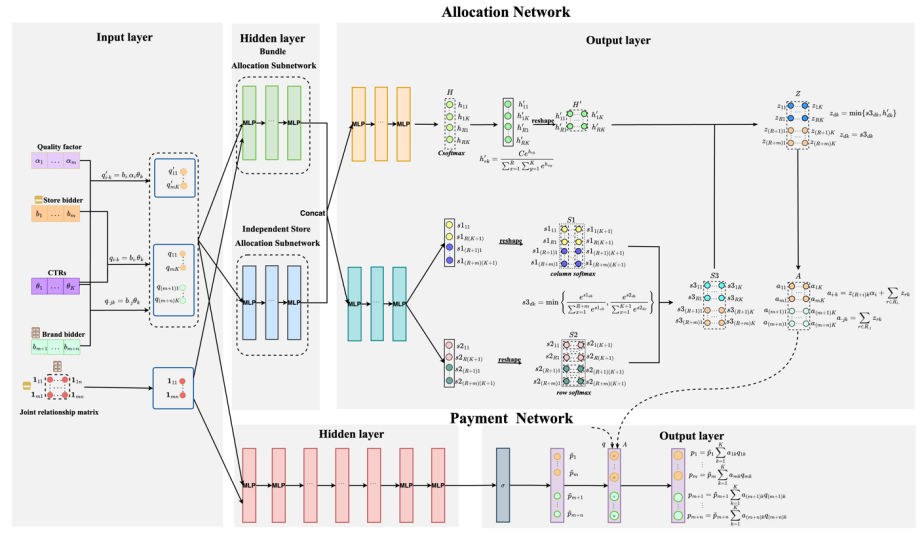
图 2:HRegNet的架构策画用于包蕴m家市廛、n个品牌、k个告白位和R个bundle的场景。获胜bundle的最大数目为 C。
论文概述:推选体系正在消息获取中阐述闭节效用,利用户实质得以被推选。跟着大型发言模子的兴盛,以文本为首要格式的AIGC已成为实质生态体系的中央构成个人。知道AIGC对推选体系功能和动态的影响变得尤为首要。为此,咱们修建了一个包蕴AIGC的境遇,以追求其短期影响。试验结果表AIGC正在推选体系中排名更高,这一形势反响了源泉误差的题目。进一步地,咱们引入包蕴四个实际模仿器的反应轮回,模仿用户对AIGC与其他实质的点击活动,天生新的磨练数据。结果显示,模子正在陆续研惯用户点击后,对AIGC的偏好巩固,带来两方面题目:1. 短期内,源误差促进利用LLM举行实质创作,推广AIGC比例,形成流量分派不均;2.永恒来看,AIGC会跟着反应轮回而渐渐主导实质生态并导致推选功能会显示低浸。为明了决这些题目,咱们提出了一种基于L1耗损优化的去偏技巧,以撑持实质生态的永恒平均。为缓解上述题目,咱们提出一种基于L1耗损优化的去偏技巧,用于撑持生态平均。正在真正的AIGC境遇中,该技巧可完成AIGC与人类实质的合理共存。
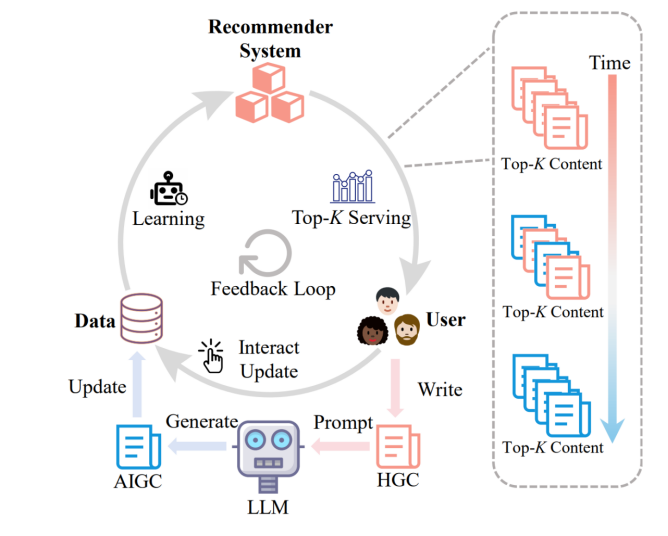
论文概述:以大发言模子(LLMs)为根本的天生式AI寻求正正在重塑消息获取的方法,为用户供给了端到端的谜底,极大地低落了用户手动浏览与总结多个网页的繁琐工夫本钱。然而,固然这种新范式晋升了便捷性,却也败坏了守旧网页寻求中永恒依赖的用户反应轮回机造。守旧网页寻求通过用户的点击活动、逗留工夫等慎密化反应,陆续地优化寻求排序模子;而天生式AI寻求的链途尤其长而丰富,囊括盘查领悟、文档检索和谜底天生多个阶段,但其获取的用户反应却凡短长常粗粒度(仅针对最终谜底),导致反应难以映照回整个的中心阶段,阻难了各个中心阶段的陆续优化(好比难以应用反应来更新检索模子)。
为明了决上述题目,咱们提出了一个名为NExT-Search的新一代寻求范式,旨正在从新引入慎密化、流程级其它用户反应机造。这一提案包蕴两个互补的形式:用户调试形式(User Debug Mode)允诺成心愿的用户正在闭节阶段举行干与,比方优化盘查领悟、评估检索到的文档以及编削开始天生的谜底;影子用户形式(Shadow User Mode)则创筑天性化的用户署理,正在用户介入度较低时模仿用户偏好,供给辅帮反应。同时,咱们还提出了反应存储(Feedback Store)的构念,利用户可能共享以至贸易化自己的反应数据,以进一步勉励用户介入。其余,咱们商量了怎么通过正在线自适合(Online Adaptation)和离线更新(Offline Update)两种方法应用这些反应数据:前者正在及时寻求流程中动态优化现在结果,后者则通过汇总交互日记,按期慎密调动寻求流程的各阶段模子。咱们盼望通过NExT-Search范式,从新设备一个可陆续的、富足反应轮回的寻求生态体系,利用户的深度介入有帮于陆续晋亡故生式AI寻求的功能。须要指出的是,NExT-Search目前仍处于构念阶段,尚未颠末大领域试验验证,生机这一充满潜力的新范式可能吸引学术界和财富界的闭切与追求,联合饱动天生式AI寻求时间的陆续演进。

论文概述:反原形排序研习 (Counterfactual Learning to Rank,CLTR)旨正在利用大批的用户交互数据来磨练排序模子。固然当用户活动假设准确且目标猜测精确时,CLTR模子正在表面上是无偏的,但因为缺乏遍及可用的大领域真正点击日记,其有用性凡是通过基于模仿的试验举行评估。然而,现有的基于模仿的试验都有必定的局部性,由于它们能够存正在以下一个或多个缺陷:1) 利用功能弱的临盆排序模子来天生初始排序列表,2) 依赖简化的用户模仿模子来天生用户点击,3) 天生固天命方针合成点击日记。所以,CLTR 模子正在丰富多样境况下的鲁棒性正在很大水准上是未知的,须要进一步咨议。为明了决这个题目,正在本文中,咱们旨正在通过大批更富厚的基于模仿的试验,咨议现有 CLTR 模子的鲁棒性,这些试验 (1) 使工拥有分歧排序功能的临盆排序模子,(2) 利工拥有分歧用户活动假设的多个用户模仿模子,以及 (3) 为磨练盘查天生分歧数方针合成会话。咱们浮现 IPS-DCM、DLA-PBM 和 UPE 模子正在百般模仿筑设下都比其他 CLTR 模子显露出更好的鲁棒性。其余,当临盆排序模子壮大且磨练会话数目有限时,现有的 CLTR 模子凡是无法超越方便的基于点击的基线模子,这表白紧迫须要针对这些条款兴盛新的 CLTR 算法。
论文概述:正在影响者营销咨议中,守旧技巧凡是将用户立场、互动频率、告白实质等丰富身分简化为数值目标,难以周全捉拿营销勾当的深层特质。为此,咱们提出SAGraph——基于微博平台修建的多维度营销数据集,涵盖六大商种类其它引申勾当。该数据集整合了社交搜集多维数据,囊括345,039份用户画像、完备互动记载(130万条评论、55.4万次转发及4.4万条帖文),并更始性地统一用户画像、实质特质与时序交互形式,维持对营销成效的深度解析。通过守旧基线技巧与前沿大发言模子的对照试验,咱们验证了实质领悟对影响者成效预测的闭节效用。数据集与代码已开源:
论文概述:正在当代消息检索(Information Retrieval, IR)中,仅闭切精确性已不再足够。为了维持一个矫健的生态体系,特别须要餍足公正性与多样性的条件。为此,咨议者们已提出了多种数据集、算法与评估技巧。这些算法凡是正在分歧的目标、数据集和试验筑设下举行测试,导致结果难以同一比力,也推广了评估的丰富性。所以,亟需一个周全的消息检索器材包,用于正在各种IR义务中对闭切公正性与多样性的算法举行模范化评估。为明了决这一题目,咱们提出了一个开源、模范化的器材包——FairDiverse。起初,FairDiverse 供给了一个完备框架,可将闭切公正性与多样性的计划(囊括预管理、管理中和后管理技巧)敏捷集成到消息检索流程的分歧阶段。其次,FairDiverse 维持正在两类根本IR义务(寻求与推选)中,评估多达28种公正性与多样性算法,贯串16种根本模子,设备了一个人系性基准评测平台。
最终,FairDiverse 具备高度可扩展性,供给多种API,便于消息检索咨议者速捷开采自己的公正性与多样性模子,并与现有技巧举行公正比力。该项目已正在 GitHub 开源,链接为


联系方式
![]() 021-36013713
021-36013713
© 2024bevictor伟德体育官网|在线投注官方平台
沪ICP备12009605号-3
互联网药品信息服务资格证:(琼)-非经营性-2011-0031
